
ScienceBase Updates - Spring 2025
Spring 2025 topics include news on maps and footprints in ScienceBase, geographic place name changes, updates to the Metadata Wizard, a tip on structuring your data release, and a featured data release.
Table of Contents
- Featured Data Release: PFAS Occurrence in Groundwater
- ScienceBase Upgrades: Updates to CatalogMaps and Footprinter
- Geographic Place Name Changes in ScienceBase
- Metadata Wizard Updates
- Did You Know? Structuring Your Data Release
Featured Data Release: PFAS Occurrence in Groundwater
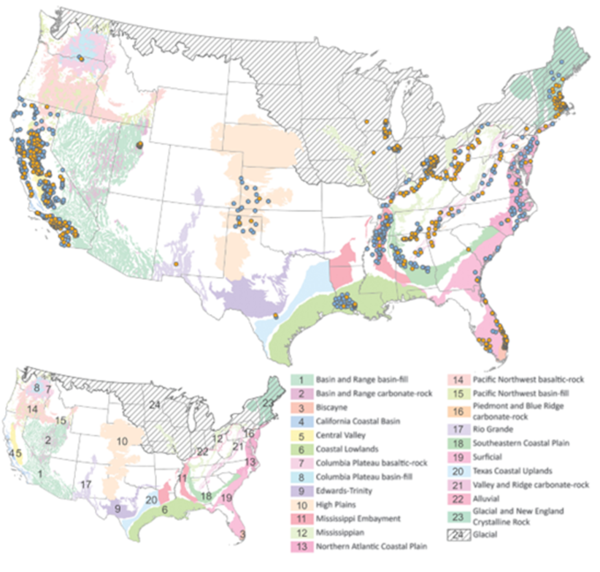
Principal aquifers of the United States (25) are overlain by PFAS sampling locations (circles) used for model training. Orange circles indicate PFAS detected; blue circles indicate PFAS not detected.
Per- and polyfluoroalkyl substances (PFAS) are a group of human-made chemicals that have become a significant environmental concern due to their widespread use in various industrial and consumer products. These substances are known for their persistence in the environment and human body, leading to potential health risks. PFAS can contaminate groundwater sources, which are critical for drinking water supplies in many communities. Understanding the occurrence and distribution of PFAS in groundwater is essential for protecting public health and ensuring safe drinking water.
In a recent data release, Tokranov and others (2024) developed a predictive model to identify where PFAS might be present in groundwater across the continental United States, helping to inform water quality management and remediation efforts. The dataset includes concentrations of PFAS, volatile organic compounds (VOCs), pharmaceuticals, and tritium in groundwater. To train their model, they looked at various factors that could influence PFAS presence, such as how urban an area is, how deep the wells are, the soil type, and how close the area is to potential PFAS sources (like airports or waste facilities). The final results of the model show where PFAS are expected to occur at a depth of groundwater typically used for public drinking supplies and private wells.
This data release and its associated publication (Predictions of groundwater PFAS occurrence at drinking water supply depths in the United States) have received widespread media attention. The related publication has been cited in 47 news articles and eight academic articles since its publication in October of 2024.
Tokranov, A.K., Bexfield, L.M., Ransom, K.M., Kingsbury, J.A., Fram, M.S., Lindsey, B.D., Watson, E., Dupuy, D.I., Voss, S.A., Jurgens, B.C., Stackelberg, P.E., Beaty, D.A., Smalling, K.L., and Bradley, P.M., 2024, Predictions of PFAS Occurrence in Groundwater at the Depth of Drinking Water Supplies in the Conterminous United States: Data and Model Archive: U.S. Geological Survey data release, https://doi.org/10.5066/P93RXTKJ.
Tokranov, A.K. et al., 2024, Predictions of groundwater PFAS occurrence at drinking water supply depths in the United States: Science, 386,748-755, https://doi.org/10.1126/science.ado6638.
As part of required security upgrades and an ongoing migration to cloud, the ScienceBase team has been making changes to the CatalogMaps and Footprinter components. While the team is working to minimize impacts to ScienceBase users, some changes can be expected.
Saving / viewing footprint info
Custom footprints (either drawn by users within the Footprinter interface or provided as uploaded shapefiles within Footprinter) will still be shown on the item page, but users should expect a delay of up to 24 hours for a nightly sync to run. Footprints selected from the default collection (e.g., states, counties, etc.) will appear immediately on the item page.
OGC Web Services
ScienceBase is migrating to a new cloud-based Geoserver instance. This will support compliance with required back-end updates and should also provide more resiliency in uptime for map services. Moving forward, users will need to perform GIS service creation for stand-alone rasters and shapefiles, using the new process available in the ScienceBase cloud file manager (see screenshot below). Please note that existing OGC map services will need to be migrated to the new Geoserver instance. The ScienceBase dev team will be performing this step on behalf of users, so no action should be required on their part. However, this process will result in updated OGC map services URLs on the item page and in the item JSON. Any process that connected to the previous URLs will need to be updated. If you have additional questions or would like to work directly with the team to manage existing services, please contact sciencebase@usgs.gov .
Starting an OGC Map Service in ScienceBase
As of March 2025, ScienceBase supports a new process to generate Open Geospatial Consortium (OGC) map services using a cloud-based Geoserver instance. Start by uploading vector data (shapefiles) or raster data (GeoTIFF files) into ScienceBase cloud storage.
This workflow creates public OGC map services. Users must ensure that any datasets do not contain sensitive information or PII prior to using this feature. After uploading the GIS files, users will need to push a copy of the files to the public-facing ScienceBase S3 storage. This step is performed from the File Manager interface or via the ScienceBase API. Users should ensure they upload and publish all component files associated with a shapefile or raster dataset.

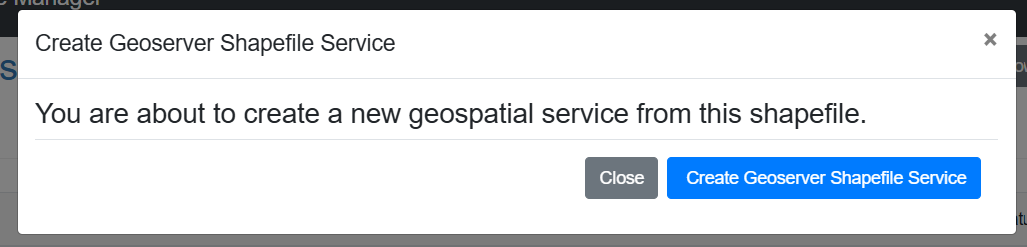
After the component files have been moved to the public bucket, find the .shp file or .tif file, and click the “Actions Menu” dropdown next to the file. Select either “Create Shapefile Service” or “Create Raster Service”.

A prompt will ask the user to confirm:
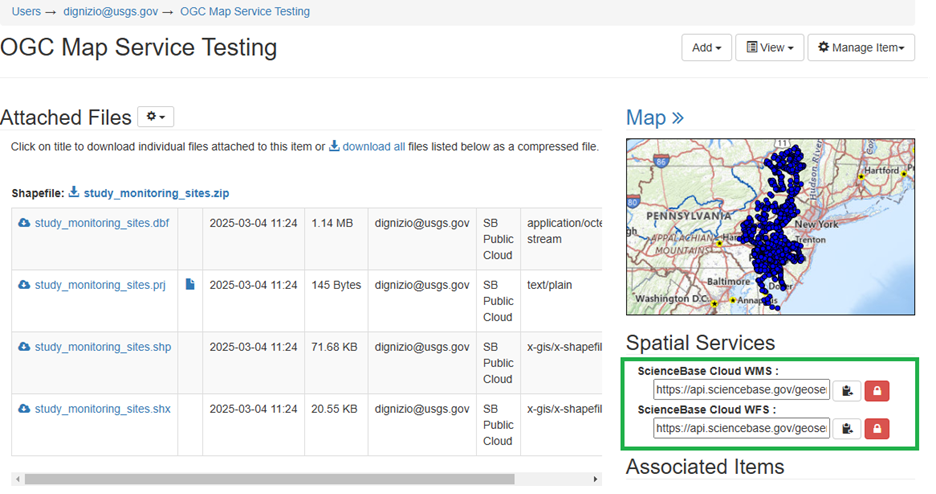
The resulting map service will be visible on the item page. The map service URLs will also be displayed.
ScienceBase uses basemaps from ESRI and the USGS National Map team and provides formal place names from the Geographic Names Information System: https://www.usgs.gov/tools/geographic-names-information-system-gnis.
To support the Department’s recent Secretary Orders #3423 (https://www.doi.gov/document-library/secretary-order/so-3423-gulf-america) and #3424 (https://www.doi.gov/document-library/secretary-order/so-3424-mount-mckinley-and-landmarks-honoring-alaskan-people), USGS has been updating various resources. As these place names are updated in authoritative sources, they will be reflected in ScienceBase.
Moving forward, formal USGS data publications should reflect updated place names. Per USGS practice, historical publications will retain the name of the geographic features as they were known at the time of publication.
Version 2.1.0 of the USGS Metadata Wizard installer for Windows (.exe) is now available on the releases page: Releases · DOI-USGS/fort-pymdwizard. An installer for Macs will be released soon.
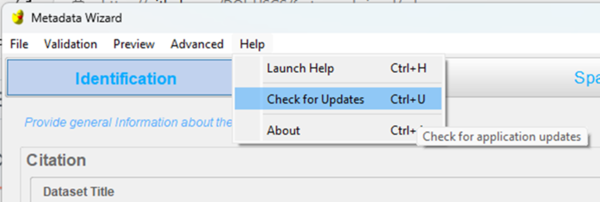
If you have already installed the Metadata Wizard, you do not need to reinstall; you can automatically pull the latest updates from the GitHub repository by selecting “Check for Updates” in the “Help” dropdown menu:
These updates include bug fixes (e.g., .xlsx files can now be parsed into an entity and attribute section), a new basemap to reflect place name changes, and an updated Python environment.
The structure of your data release is just as important as the structure of the data and metadata that it hosts. How your data release is organized determines how data users discover your data, how they access and explore data repositories like ScienceBase, and how they interact with your data. To ensure that users are getting the most out of your data, here are some best practices on how to structure a data release.
The framework for a data release is flexible to fit the needs of the data author--do you want users to discover your data as a single package, or as individual data sets? Do the data release components require the contents of the entire data release, or could they have some utility independent from the data release? These are questions that can help you determine whether you should structure your data release with child items. A good strategy is to organize your data release based on the number of data and metadata files you are publishing.
If you have one metadata record to describe your data, you can upload both your data and metadata files directly to the data release landing page. However, if you have multiple metadata records and data sets, you can employ nested subpages under the landing page, or "child items". Each nested page can host one metadata record and its associated data files, allowing for downstream users to pick and choose datasets within a given data release.
The Science Data Catalog (SDC) can only harvest one unzipped metadata record per ScienceBase item. The ScienceBase Data Release Team encourages authors to include a summary metadata record on the parent landing page that describes the entire product even if there are child items with individual metadata records describing discrete datasets. All metadata records should have unique and descriptive titles.
Whether you have one metadata record describing an ASCII text file or three data sets and a shapefile with their own individual metadata records, there is a way to tailor a data release to your needs. As an additional resource, you can watch this video to help you determine the best way to structure and document your data releases.: https://www1.usgs.gov/csas/training/StructuringUSGSPublicDataRelease/index.htm