
PIR Tool FAQ
The Persistent Identifier Registration (PIR) Tool can be used to generate or register a unique persistent identifier (PIDs), and optionally, unique persistent URLs, for various artifacts produced in USGS. Below are a list of FAQs about the PIR Tool.
Frequently Asked Questions
- How do I use the PIR Tool?
- Do PIDs have to be registered in the USGS PIR Tool?
- In my PIR Dashboard, what is the 'PURL' field in my PID record for?
- Why is a PID now required for my metadata record?
- Are metadata PIDs needed for metadata already published prior to this new requirement?
- When does this policy for assigning a metadata PID go into effect?
- Is there a specified format for USGS metadata PIDs?
- Why can’t the Digital Object Identifier (DOI) be used from my metadata for this purpose?
- Where is the generated PID inserted in the XML metadata file?
- Which USGS repositories are using custom-generated PIDs to assign to their metadata?
- Who is responsible for registering a metadata PID and inserting it into the metadata file?
- Will I need to manage my PID record after it's generated?
- How do I update a published metadata record after the PID has been assigned?
- Can I delete a PID in the PIR Tool?
- Why am I immediately logged out when trying to log into this tool?
How do I use the PIR Tool?
To assign a metadata PID to an individual metadata record, you will need the following information:
- the Data Source (center or program) publishing the data
- the Title of the data as it appears in the metadata
Login to the USGS Persistent Identifier Registration (PIR) Tool using your Active Directory credentials.
After login, click "Create / Register a PI" button:

The main menu will appear as a pop-up window:
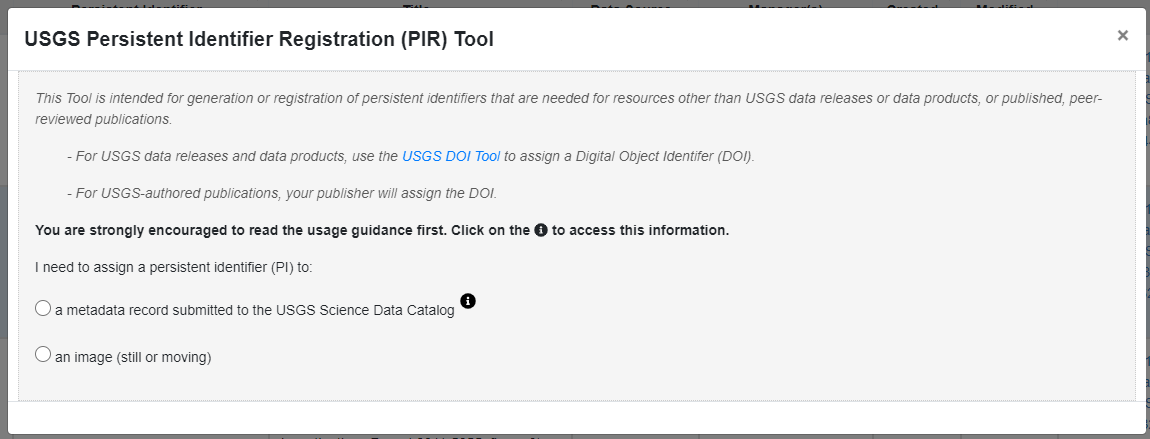
Information is available within the tool by clicking on the "i" medallion to the right of the field:
Click the "Close" button to return to the main window.
Select the option to obtain an identifier for "a metadata data record submitted to the USGS Science Data Catalog". Next, select the option "generate the identifier for me"; the second option is used only by USGS repository or metadata aggregation WAF managers:
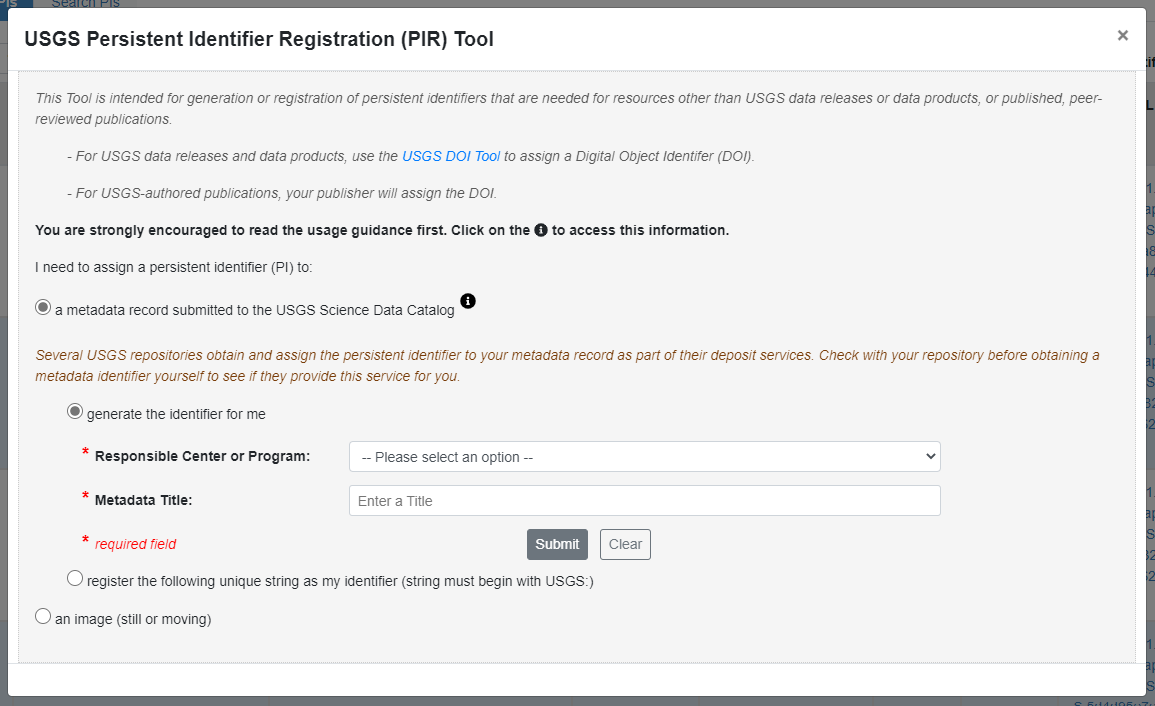
You will now be asked to select the responsible center or program associated with the data release, and the title of the data as it appears in the XML metadata record. It is important that the title listed in the PID match what will be extracted from the title element in the primary citeinfo section of the metadata.
Click 'Submit.' You will then see a confirmation window.
If everything looks correct, click 'Submit'; otherwise, click 'Go Back' to correct any errors.
You will then see a confirmation window that provides your new PID. Click 'Copy PI' if you want to copy and paste the PID into your metadata XML file now. Then click 'Close and return to Dashboard.'
Your My PIDs tab in your Dashboard will now include your new record:

Your Dashboard will contain all records that you have created yourself, as well as any records for which you were added as a (co)Manager. If you want to search all records in the PIR Tool, you can click on the 'Search PIs' tab to do this:
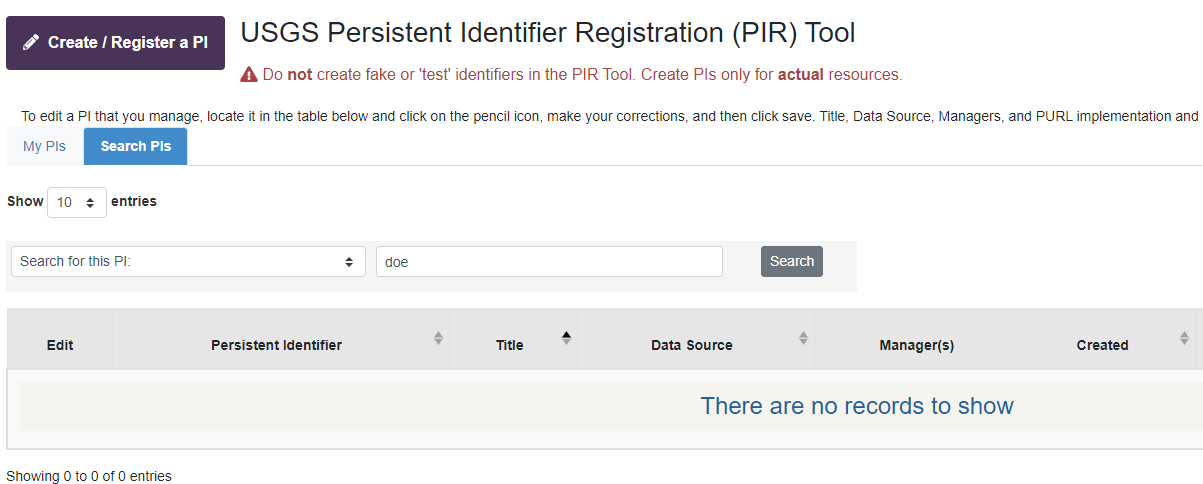
You can edit any record for which a pencil icon appears in the 'Edit' column.
Do PIDs have to be registered in the USGS PIR Tool?
Yes, all USGS metadata PIDs must be registered in the PIR Tool, even if they are custom-generated by a repository.
Upon harvest of your metadata, the SDC harvester will verify that the PID in your metadata record is registered to the PIR Tool, and is unique to your metadata record.
If the PID in the metadata record is found to not exist in the PIR Tool, or if the PID is malformed (e.g., typo, missing USGS: prefix), the record will fail the harvest process, and will not be included in the Science Data Catalog index.
In my PIR Dashboard, what is the 'PURL' field in my PID record for?
A persistent URL, or ‘PURL,’ is a permanent URL that can be applied to an online object, and then managed behind the scenes to persist if the actual location of the online object moves over time. A Digital Object Identifier (DOI) is actually a specific instance of a PURL.
The PIR Tool creates a PURL from your metadata PID when you register it.
Science Data Catalog 3.0 harvests your metadata record from your chosen USGS repository, it will store the full text of that original metadata in the Cloud, and then tell the PIR Tool the exact file path to that full metadata in the Cloud; that full file path will become the actual online location that your PID’s PURL will point to. Just like a DOI, your PID PURL will always point to the most recent full text version of your metadata record, wherever that PURL may be used. For example, if the PURL assigned to your PID is https://www1.usgs.gov/pir/purl/USGS:abcdefg1234567, that PURL will always be a permanent link to the full text of the metadata that lives in the SDC. If the SDC moves the location of that full text metadata to another Cloud location, the new location will be mapped automatically that PURL, but the PURL itself won’t change.
When you update your metadata record and replace the previous version, the SDC will replace the previous full text metadata record in the Cloud with the new version, so that the most recent version will always be located at the PURL endpoint.
You cannot edit the PURL itself because the PURL’s format is generated automatically from your metadata PID. Unlike your DOI for your data release, for which you have to enter the Location URL where the data release actually lives online, the Location URL that your metadata PURL points to is controlled by the SDC when it stores the full text of your metadata record in the Cloud. This location will always be managed directly by the SDC.
Related Question: Why does SDC need a full-text copy of my metadata with a PURL assigned to it, when a full-text version already lives in the repository with my data release?
The new version of the SDC will index only selected fields from your metadata record in the Catalog’s index, rather than the full text of the record. This will improve the speed and efficiency of the SDC search, and remove a lot of the ‘noise’ in search results that is associated with term matches coming from metadata fields that aren’t specifically oriented towards discovery of data. When metadata from the SDC index are sent downstream to the federal catalogs, they will use the same metadata fields that power the SDC for their own indexing; however, the Geoplatform wants access to the full text of original metadata in order to perform additional parsing of that full metadata for fields specifically associated with geospatial concepts and services.
In order to provide a consistent and persistent access point for the Geoplatform to get to these records, the SDC will point Geoplatform to all full metadata records in the SDC’s Cloud folder. This will ensure that the URL to these full text metadata records won’t change over time. It will also eliminate intensive programmatic harvests by Geoplatform of the actual USGS repositories and metadata WAFs for access to these records, which can result in performance issues for those systems in response to heavy traffic from that harvester.
An added bonus of having a persistent URL for your full text metadata record is that you can connect your DOI for your data release to your metadata PURL. In the USGS DOI Tool, you can add your metadata record’s PURL as a Related Identifier for your DOI record, using the relationType “hasMetadata” in conjunction with your metadata PURL (e.g., https://www1.usgs.gov/pir/purl/USGS:abcdefg1234567). Your metadata link in your repository might change over time, or your data release might move to a different repository or archive at a later date, but as long as the SDC is storing a copy of your most recent metadata in the Cloud and pointing to it with the PURL associated with your metadata PID, that metadata record will persist.
Why is a PID now required for my metadata record?
The USGS Science Data Catalog (SDC) currently contains more than 23,000 metadata records, representing data that have been released by the bureau for more than a decade. The annual rate of data release since open access policies were formalized in FY17 continues to increase, and the metadata for these data are not only included in the SDC, but are also sent ‘downstream’ by the SDC to the federal data catalogs (Dept. of the Interior Catalog, data.gov, and, where relevant, Geoplatform.gov) and to other public systems such as Google Data Search and DataONE. As the USGS collection grows over time, and metadata are updated to reflect data versioning and metadata improvements, metadata uniqueness in these catalogs becomes a challenge. Right now, there is no specific indicator of ‘uniqueness’ in the metadata generated within USGS. Most of our metadata continues to be created in the FGDC Content Standard for Digital Geospatial Metadata (CSDGM), which does not include a specific identifier for the metadata record itself in the schema. A limited number of ISO metadata records have been produced in USGS, and while the ISO standard does include a specific field for metadata identifier, it is often not populated.
The lack of formal metadata identifiers in USGS metadata forces most catalogs to leverage an existing metadata field – usually the title within the citation array – as the unique identifier for a record. When a metadata catalog harvester reads an XML metadata file, it usually looks at the title field and the metadata record’s date to determine whether this record is already known to the catalog index. If the record appears to be ‘new’ (not seen before), the metadata record is ingested as a new addition to the catalog. If the metadata record appears to be previously ‘known’ to the catalog, the harvester looks at the metadata date of the record to determine if that date is different from the metadata date that was read at the previous encounter with the record. If the date is more recent, the metadata are interpreted as ‘updated,’ and the metadata are re-harvested and then replace the previous version in the catalog. If the metadata date is unchanged since the harvester’s last encounter with the record, the metadata are determined to be in the same state, and the metadata are not re-harvested.
As you can imagine, titles are relatively poor indicators of the uniqueness of a particular metadata file. Many data releases included multiple data files with very similar titles; as well, some long-term data are released incrementally, with the same, or highly similar titles. Data and metadata versioning can also introduce difficulties with changes to title fields, such that older and newer versions of the metadata are difficult to track. It is important that duplicate metadata records not exist in these catalogs, and that the catalog harvesters are prompted to add, remove, or replace metadata when versions are introduced. A unique metadata identifier becomes critical for the catalogs to interpret the uniqueness of the record, and its currency. It is therefore vital that the metadata record be assigned a unique metadata identifier, and that its metadata date always be maintained and updated when the metadata are versioned.
The federal catalogs are requesting that metadata persistent identifiers be included in metadata being sent downstream from the bureaus, so that they can effectively manage our collections of metadata, adding new records and updating/deleting versions as appropriate.
In the forthcoming new version of the USGS Science Data Catalog, the presence of a metadata identifier within the XML of the record will be required. This requirement will apply to all new records, as well as records previously published to the SDC by your repository or metadata system’s Web Accessible Folder (WAF).
Are metadata PIDs needed for metadata already published prior to this new requirement?
Every USGS metadata record, including those already published to the Science Data Catalog through repositories and WAFs, must include a unique persistent identifier in order to be harvested into the forthcoming new release of the USGS Science Data Catalog. Records that do not have a valid, unique, registered USGS metadata identifier will not be included in Catalog.
SAS is working with existing USGS repositories and WAFs to register metadata PIDs and insert those PIDs in the metadata for already published data releases. We are providing tools and support to get this work done in advance of the release of the new catalog.
Bottom line: if your metadata are already published in a USGS repository or metadata WAF, you yourself will not be responsible for assignment of the PID in that record.
When does this policy for assigning a metadata PID go into effect?
Metadata PIDs should be registered and assigned now for any new data releases.
Is there a specified format for USGS metadata PIDs?
All USGS metadata PIDs will start with “USGS:”. This format was specified by the federal data catalogs, who will be relying on these PIDs to help them manage USGS holdings in those catalogs. Applying the “USGS:” prefix will help managers of those catalogs immediately identify our metadata records in their systems.
If the “USGS:” prefix is missing in the metadata record’s PID, the record will fail the Science Data Catalog harvest process. Make sure your PID is complete and correct when inserting it into the metadata XML.
PIDs generated by the PIR Tool will be a 36-character alpha-numeric sequence preceded by “USGS:”.
PIDs custom assigned by specific repositories will contain the USGS: prefix, followed by a repository identifier, followed by the repository’s custom, unique string. For example, a PID assigned by the Alaska Science Center Repository would be of the format “USGS:ASC:[custom identifier string].”
Generally speaking, only repository staff assigning PIDs to records should use the option for custom PID assignment. If you are tasked assigning the PID to your own metadata record, choose the option “generate the identifier for me,” unless you are specifically directed to perform the custom PID assignment by the manager of your chosen repository.
Why can’t the Digital Object Identifier (DOI) be used from my metadata for this purpose?
There are two deficiencies with this approach:
- Many older USGS data releases do not have DOIs assigned to them, and therefore no data release DOI appears in the metadata. DOI assignment became a requirement on October 1, 2016; prior to this, assignment of DOIs (which have been available in USGS since 2014), was optional. Retrospective assignment of DOIs to older data releases, while strongly encouraged, is not required. Approximately 1/3 of our USGS metadata records in the SDC precede the 2016 data management requirements, with no data release DOI displayed in the metadata.
- For some USGS data releases, there is not a 1:1 relationship between a DOI and a single metadata record. Some data releases have a single DOI assigned to a single dataset with a single metadata record; other data releases have a single DOI assigned to a collection of datasets, each with their own metadata record. In the latter cases, the same DOI could appear in multiple metadata records, and would therefore not be usable as the unique persistent identifier for that metadata record.
It is therefore necessary that each individual metadata have its own identifier that is unique to, and always present in, the actual XML of the record.
Where is the generated PID inserted in the XML metadata file?
Placement of the PID depends upon the metadata standard you are using.
FGDC CSDGM:
The CSDGM standard does not include a specified field for a metadata identifier. Because CSDGM records must pass validation, we cannot create and add a new field to our XML files for this purpose, because any field not part of the original standard would cause the record to fail a validation process. Instead, we must leverage an existing field in the standard that can serve this purpose, in addition to its original, intended function.
The USGS Metadata Reviewers Community of Practice discussed this issue, and agreed that the best location for the metadata PID would be in the theme keyword array, because this array is repeatable, the allowable values are alpha-numeric, and because any validation on these fields would not result in a failure to parse the PID. The PID can be added, along with true thematic keywords, in each record.
The PID must be entered with a theme keyword thesaurus <themekt> value, and the theme keyword <themekey>. The information would be entered as follows:
<themekt>USGS Metadata Identifier</themekt>
<themekey>USGS:5aa0648-ee4b-0b1c392e-6c0c-fvv89rt5-0dko</themekey>
The theme keyword array for the metadata PID can be placed in any order in the larger set of theme keywords used. In other words, you can make your metadata PID the first set of theme keywords in your record, or the last. Just make sure that it is a separate keyword array, and that the themekt is entered exactly as specified above.
The Science Data Catalog harvester will look specifically in the <keyword> array of a submitted CSDGM record for the presence of the metadata PID, and specifically for the required syntax in themekt and themekey.
ISO 19115-x
The ISO standard has a dedicated field that is used specifically for a unique metadata identifier. This field is MI_fileIdentifier, and is contained within the MI_Metadata section at the beginning of the record; only the PID itself will need to be inserted into this field, as the field already expresses to the SDC harvester that its value constitutes the identifier for the metadata record.
Which USGS repositories are using custom-generated PIDs to assign to their metadata?
Some USGS repositories expressed a desire to re-use their internal data system identifiers as the basis for the metadata PIDs, in order enable easy mapping between a PID and the item in their systems. These repositories will be using the PIR Tool option to ‘register the following unique string as my identifier’ within the PIR Tool. In most cases, these repositories are going to do the PID registration and metadata update themselves; however, in some cases, the repository may give an individual metadata author the custom PID and request that the author register the PID in the PIR Tool. Your repository will inform you if this is required.
These USGS repositories will be using custom unique PIDs that they will register in the PIR Tool:
- ScienceBase (for data releases that use the formal ScienceBase Data Release process)
- Alaska Science Center Repository
- Earth Explorer
- The National Map
These USGS repositories will be using the PIR Tool to directly generate random, unique PIDs for metadata records:
- Coastal & Marine Geoscience Data System
- Water NSDI Node
- EROS data releases that are not through Earth Explorer
If you are publishing your data release to a non-USGS repository:
- you must individually obtain a metadata PID from the PIR Tool (choosing ‘generate my identifier for me’), insert it correctly into your metadata record, and submit the metadata to the Science Data Catalog via the Individual Metadata Upload (IMU) Tool.
Who is responsible for registering a metadata PID and inserting it into the metadata file?
Most USGS repositories and metadata aggregation managers have determined that they will provide this service to you when you submit your final metadata and data files for release.
Some USGS repositories are still making a determination of responsibility. In a few cases, the individual metadata author will need to obtain the metadata PID and also insert it correctly into their metadata file prior to its publication.
Please see the chart below for the latest information available as to the party responsible for generating the metadata PID in the PIR Tool, and inserting the PID into the metadata. We will update this chart as we receive more information.
The chart below details the responsible party for registering a PID for, and inserting the PID in, a metadata record.
| Repository Name | Repository-generated metadata PID? | Author-generated metadata PID? |
|---|---|---|
| ScienceBase (through the ScienceBase Data Release Process) |
Yes |
No |
| Alaska Science Center Repository | Yes | No |
| Coastal & Marine Geoscience Data System | Yes | No |
| Water NSDI Node | Yes | No |
| EROS | Yes, for data release in Earth Explorer* | Yes, for all other EROS data releases* |
| National Geospatial Program / The National Map | Yes | No |
| Approved non-USGS repository (metadata must be submitted by you to the Individual Metadata Upload (IMU) Tool) | No | Yes |
If your repository/data system is not listed here, contact the manager of that system to determine how they intend to proceed with assignment of metadata persistent identifiers.
*More specific guidance will be communicated directly to EROS staff by Earth Explorer and EROS metadata WAF managers.
Will I need to manage my PID record after it's generated?
Because the PIR Tool requires only two pieces of information - the Data Source (center/program) responsible for the data release, and the title field as it appears in the metadata - you won't need to make any future changes to the information in the PID record unless you change the title of the metadata in the XML in a future update.
If the title is changed, you should update the PID information in the PIR Tool to reflect the new title as it appears in the metadata.
If the name of the Data Source (program or science center) responsible for the data release changes as a result of a mission area or bureau reorganization, the SAS SDM Team will work with the repositories and metadata aggregation WAF managers to perform these updates programmatically to affected records.
You can add a co-manager to your PID record from the PIR Tool Dashboard at any time. If a person departs your center/program and is the sole owner of any PIDs in the system, contact us to request that these items be transferred to another person in your office.
How do I update a published metadata record after the PID has been assigned?
For metadata being updated due to an error or change to the data or metadata, you should make sure that you are using the most current version of that record that includes your metadata PID when making the updates to the XML file.
If your chosen repository or metadata WAF assigned the metadata PID, treat the copy in that repository or system as your authoritative copy, and download that version to make your edits. This will ensure that you have the correct PID in your updated copy of the metadata that you provide to the repository or WAF to replace the previous version.
If you are responsible for assigning your metadata PID yourself, keep the authoritative copy of the XML with the metadata PID available to you locally, so that you can make future changes while retaining the PID in the new version.
Make certain that the metadata date in your XML is updated to reflect the date of the changes in the metadata. Failure to update the metadata date will result in your changes not being read by the SDC and the downstream catalogs.
Once your updated metadata record is republished to your repository or metadata aggregation WAF, the previous version of the metadata should be removed from that harvest point by your repository/WAF manager. When the SDC harvester 'reads' this new version, it will recognize your metadata PID from previous harvests, but it will also see from the revised metadata date that your metadata file has been changed in some way. The harvester will then read the full text of your metadata record, and replace the version previously stored in the SDC index with this new version.
SDC will then pass on this updated information to the downstream federal catalogs, Google Data Search, and other sources, and they will replace the prior version of the metadata with the newest version.
Can I delete a PID in the PIR Tool?
No. We are not allowing a delete function in the PIR Tool, in order to prevent accidental deletions, as this would introduce problems if the SDC harvester could no longer find a PID in its registry. The choice to not delete PIDs also ensures that a PID can never be duplicated at a later date.
It is unlikely that a delete function is needed. If a metadata record is permanently removed from a harvest endpoint due to a decision to withdraw the data release, the metadata will be removed from the SDC upon the next harvest of that repository or WAF endpoint, because the item with that PID will no longer be found. If that record is returned to the harvest endpoint at a later date, the metadata will be re-read and will be treated as a 'new' record from that endpoint.
Why am I immediately logged out when trying to log into this tool?
Browsers store text files (cookies) that they use to help with authentication. Sometimes those cookies go 'stale' and will cause you to be redirected to the login screen after a login attempt. You may see the message, "You got redirected to login page because your session expired."
In order to log in, you will need to remove the stale cookies using the following steps:
1.) Click the lock icon to the left of the browser's address bar and select 'Cookies.'

2.) Select the parent cookies folder under the URL www1.usgs.gov and click 'Remove.'

3.) Once you have removed the cookies, try to log in again.